



Decentralized compute networks promise something powerful: access to a global pool of GPUs without relying on centralized cloud providers. But for many infrastructure engineers, the first question is not about scale or cost.
In distributed systems, the real question is not whether machines fail. They always do. The real question is what the system does when they fail.
With distributed environments, nodes go offline, network connections drop, and hardware behaves unpredictably. In centralized cloud platforms, providers like AWS or Google Cloud handle this abstraction behind the scenes. Their infrastructure is tightly controlled and standardized across large data centers.
With decentralized systems, the situation is very different. Compute resources come from independent operators running machines across different locations, networks, and hardware configurations.
This introduces a distinct engineering challenge: how to maintain decentralized compute reliability in a P2P environment where you do not control the underlying hardware.
If a network cannot recover automatically from node failures, developers end up spending more time managing infrastructure than running workloads. Distributed compute reliability is what ultimately separates experimental compute marketplaces from production ready networks.
What Reliability Means in Pay Per Use Compute
In decentralized environments, reliability is not simply about uptime. For developers running pay per use compute jobs, reliability means workloads behave predictably even when the underlying infrastructure changes.
Engineers typically care about four things:
Job Completion
The compute job finishes even if the node originally assigned to the task goes offline.
Predictable Runtimes
Jobs should not stall due to unstable hardware or inconsistent networking.
Consistent Outputs
Running the same workload with identical inputs should produce identical outputs.
Clear Failure Handling
The system should distinguish between application errors and infrastructure failures such as node crashes or memory exhaustion.
Infrastructure teams often measure this through Goodput, which is the percentage of time GPUs spend performing useful computation instead of waiting for stalled nodes or failed processes. In distributed environments, maximizing goodput is essential for delivering reliable GPU compute and maintaining stable GPU compute availability across the network.
Why Decentralized Compute Networks Are Hard to Run Reliably
Unlike centralized cloud platforms that operate inside standardized data centers, decentralized networks aggregate compute resources from independent providers. This introduces several reliability challenges.
Node Churn
In decentralized systems, machines can join or leave the network at any time. Operators may shut down hardware, lose connectivity, or reallocate GPUs to other workloads. If a node disappears mid job, the system must detect the failure and reroute execution quickly to maintain distributed compute reliability.
Hardware Heterogeneity
Decentralized networks combine many different types of GPUs and system configurations. Some nodes may run high end data center GPUs while others use consumer hardware. Differences in drivers, CUDA versions, and system environments can cause compatibility failures if workloads rely on the host environment. This is why containerized compute jobs are essential. They package the full runtime environment so workloads execute consistently across heterogeneous infrastructure.
The Noisy Neighbor Problem
In some environments, multiple workloads run on the same machine. When processes compete for CPU threads, disk bandwidth, or network interfaces, workloads may stall unexpectedly. Reliable compute systems must isolate workloads carefully to prevent resource contention.
Fixing Reliability through Job Orchestration and Node Benchmarking
Modern distributed systems assume that infrastructure failures will happen. Instead of preventing every failure, they focus on detecting issues quickly and recovering automatically.
Ocean Network applies these principles through a coordinated architecture that combines node benchmarking, job orchestration, and containerized execution.
Node Eligibility through Node Benchmarking
Before a node can accept jobs, it must prove its capabilities. The Ocean Network Dashboard maintains a benchmarking leaderboard where nodes are ranked based on their performance across GPU, CPU, and bandwidth tests. Nodes must consistently pass these benchmarks to remain eligible for the compute catalog. This ensures developers run workloads on machines that meet baseline performance expectations.
Ocean Orchestrator: Local IDE Integration
To bridge the gap between local code and remote GPUs, Ocean Orchestrator integrates directly into development environments such as VS Code, Cursor, and Windsurf. This allows developers to launch containerized compute jobs directly from their editor.
Key capabilities include:
- Connection Monitoring
A dedicated “Check” button provides a real-time heartbeat. If the node status is not healthy, the system flags the environment before the job is submitted. - Containerized Execution
The Orchestrator packages code, dependencies, and runtime requirements into isolated containers. This ensures consistent execution across diverse hardware environments.
Smart Escrow and Payment Logic
Reliability also applies to the transaction layer. Ocean uses an escrow based payment system where funds are locked only when the Start Job button is clicked. If a node becomes unavailable before execution begins, the developer is not charged.
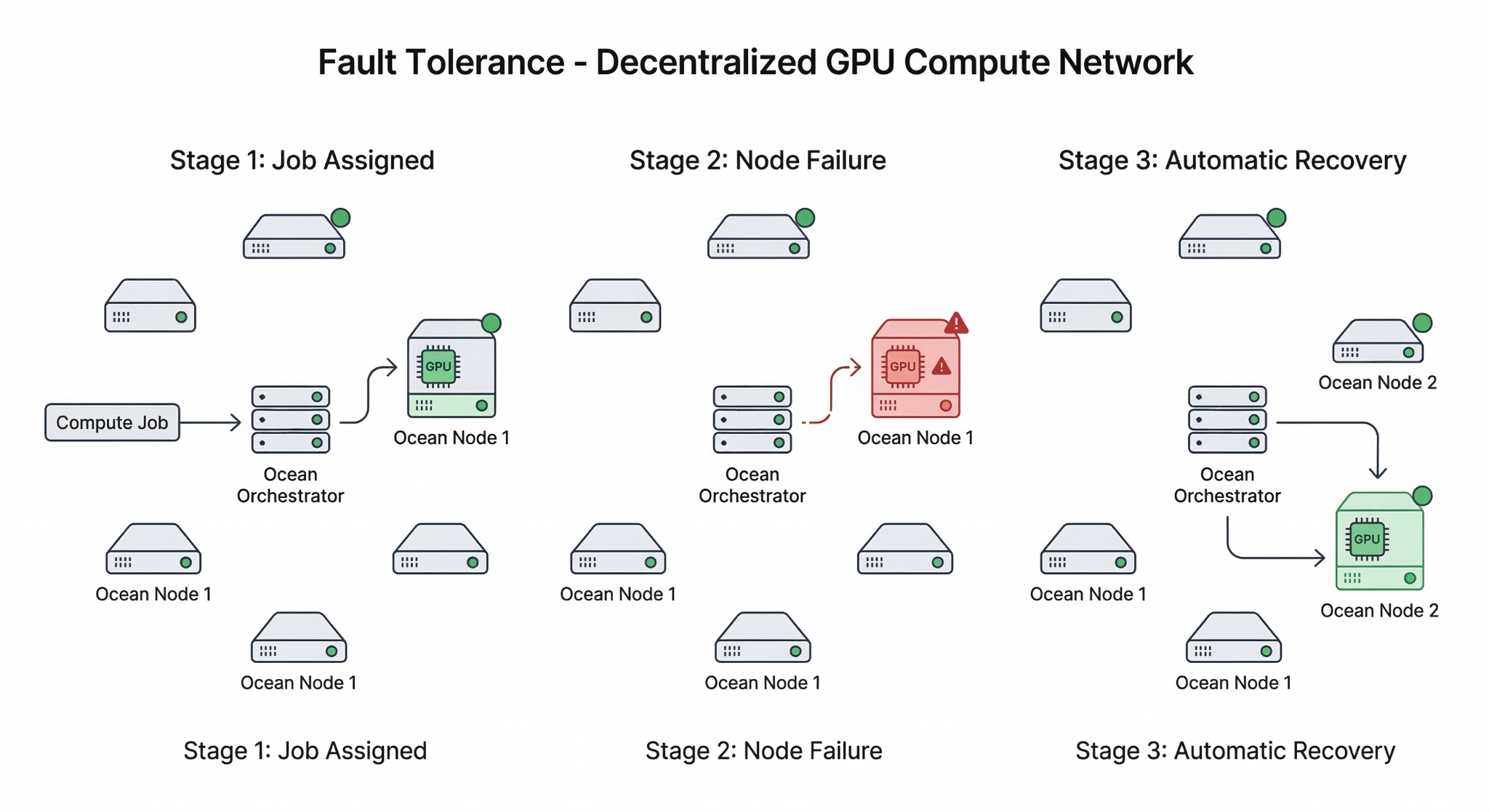
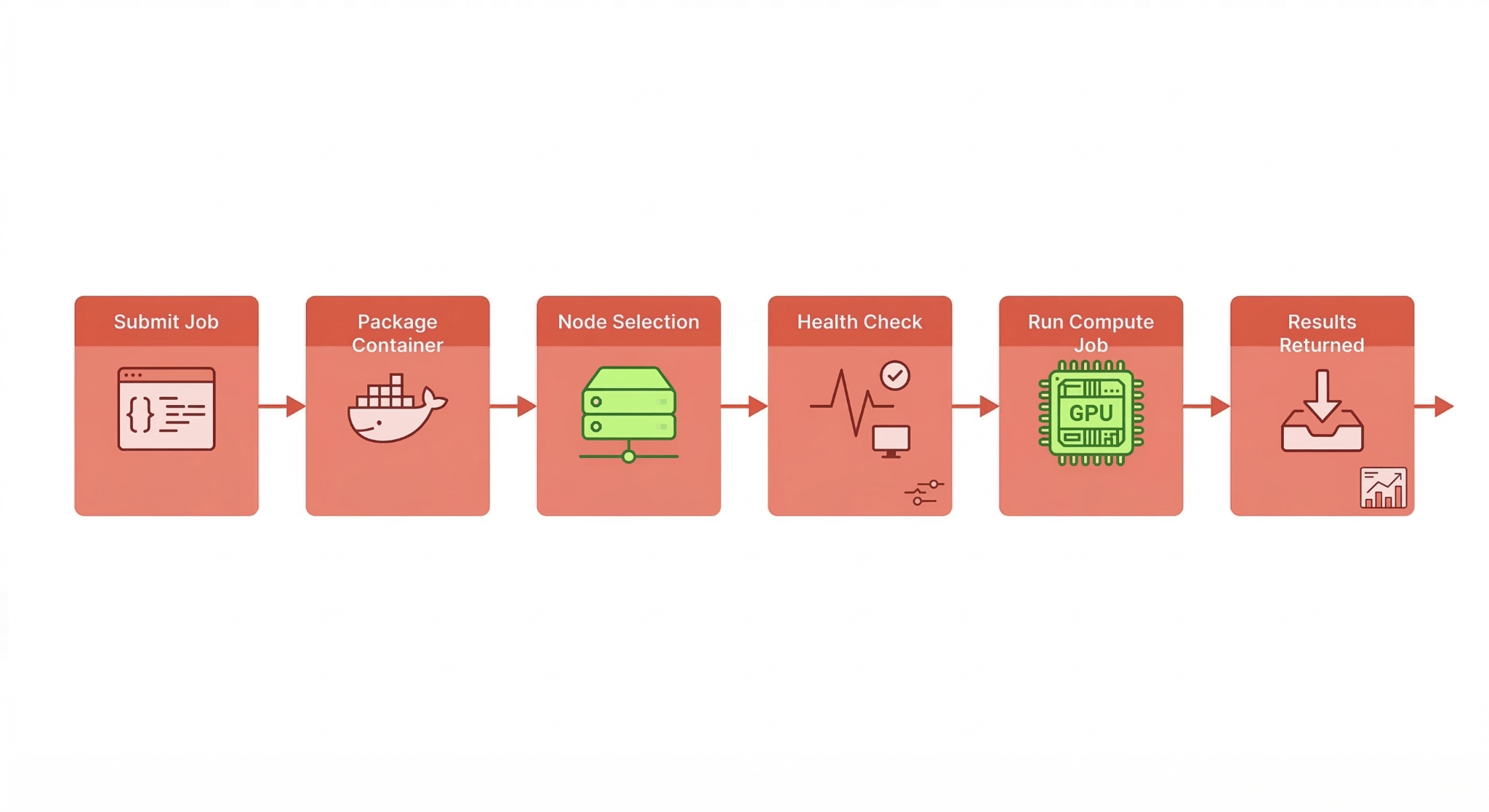
The Lifecycle of a Distributed Compute Job
When a developer launches a workload through Ocean Orchestrator, several steps happen behind the scenes.
Job Packaging
The workload, dependencies, and runtime environment are packaged into a container.
Container Execution
The workload runs as a containerized compute job on the selected Ocean Node.
Node Health Monitoring
Heartbeat signals and container status updates ensure the job is progressing normally.
Failure Detection
If the node becomes unresponsive or the container crashes, the orchestration layer detects the failure.
Retry or Reassignment
The developer can quickly re-trigger the workload on another node by selecting a different environment ID.
This lifecycle allows workloads to remain portable and recoverable across a decentralized pool of compute resources.
What Happens When a Node Fails?
Failures are expected in distributed systems.
When a node running a job becomes unavailable, the orchestration layer detects the dropped heartbeat or a non-responsive container.
The Ocean Orchestrator streams real-time logs to the developer’s IDE output console, providing visibility into the cause of the failure, whether it is an out-of-memory condition, a container crash, or a network interruption.
Because workloads are containerized and portable, developers can quickly reroute the job to another node and continue execution. Once the job reaches a Completed state, the results and execution logs are automatically synced back to the local results directory.
How Compute to Data Improves Reliability
Traditional machine learning pipelines often require transferring large datasets to the compute environment before processing can begin. These large data transfers introduce significant reliability risks. Moving terabytes of data across networks increases the chances of timeouts, partial transfers, and network failures.
Ocean Compute to Data architecture reverses this model. Instead of moving datasets to the compute node, the compute travels to the location where the data already resides.
Only two things move across the network:
- the containerized resources
- the final outputs
Large dataset transfers are one of the most common failure points in distributed AI pipelines. By minimizing network movement, Compute to Data significantly reduces failure risks, improving reliability for workloads such as batch inference at scale and reliable model inference.
What Developers Should Expect
Even with strong orchestration systems, distributed compute requires resilience-aware application design. Developers should implement checkpointing for long-running workloads to prevent progress loss if a node fails.
While Ocean Network orchestration handles scheduling, execution, and node selection, developers should still monitor GPU compute availability through the dashboard to ensure their chosen environment meets the requirements of their workload.
Getting Started: From Test to Scale
You can experience the reliability of decentralized compute without any upfront cost and follow these three simple steps.
Free Compute
Use the Ocean Network dashboard to find nodes offering free GPU or CPU test compute. This allows developers to test containerized workloads and verify code logic without paying for GPU time.
Paid Compute
Once workloads are validated, developers can scale to more powerful GPUs such as A100s or H100s using tokens or the fiat on-ramp.
Onboarding
With Google or social login support and Smart Wallet integration, onboarding into the network now resembles the experience of traditional cloud platforms. No crypto expertise required.
From running your first containerized compute job to scaling workloads across multiple nodes, Ocean Network provides a practical path toward reliable decentralized GPU compute. We recommend starting from our docs at docs.oncompute.ai, and following us on X at @ONcompute to stay updated on the latest announcements and features.








